总结一下java中的序列化与反序列化的原理。
序列化&反序列化产生的原因 为什么会有反序列化的存在?
在 为什么要用序列化与反序列化 之前我们先了解一下对象序列化的两种用途:
把对象的字节序列永久地保存到硬盘上,通常存放在一个文件中;
在网络上传送对象的字节序列。
我们可以想想如果没有序列化之前,又是怎样一种情景呢?
举例:
Web 服务器中的 Session 会话对象,当有10万用户并发访问,就有可能出现10万个 Session 对象,显然这种情况内存可能是吃不消的。
于是 Web 容器就会把一些 Session 先序列化,让他们离开内存空间,序列化到硬盘中,当需要调用时,再把保存在硬盘中的对象还原到内存中。
我们知道,当两个进程进行远程通信时,彼此可以发送各种类型的数据,包括文本、图片、音频、视频等, 而这些数据都会以二进制序列的形式在网络上传送。
同样的序列化与反序列化则实现了 进程通信间的对象传送 ,发送方需要把这个Java对象转换为字节序列,才能在网络上传送;接收方则需要把字节序列再恢复为Java对象。
那么我们就可以知道Java 序列化和反序列化,首先实现了数据的持久化,通过序列化可以把数据永久的保存在硬盘上;其次,利用序列化实现远程通信,即在网络上传递对象的字节序列。
对象流 说到java的反序列化就要先提到ObjectInputStream 和OjbectOutputSteam这两个对象的处理流,他们用于存储和读取基本数据类型数据或对象的处理流。它的强大之处就是可以把Java中的对象写入到数据源中,也能把对象从数据源中还原回来。
序列化:用ObjectOutputStream类 保存基本类型数据或对象的机制ObjectInputStream类 读取基本类型数据或对象的机制
注意:ObjectOutputStream和ObjectInputStream不能序列化static和transient修饰的成员变量
对象序列化机制允许把内存中的Java对象转换成平台无关的二进制流,从而允许把这种二进制流持久地保存在磁盘上,或通过网络将这种二进制流传
序列化的好处在于可将任何实现了Serializable接口的对象转化为 字节数据,使其在保存和传输时可被还原
序列化是 RMI(Remote Method Invoke – 远程方法调用)过程的参数和返回值都必须实现的机制,而 RMI 是 JavaEE 的基础。因此序列化机制是JavaEE 平台的基础
如果需要让某个对象支持序列化机制,则必须让对象所属的类及其属性是可序列化的,为了让某个类是可序列化的,该类必须实现如下两个接口之一。NotSerializableException异常
Serializable
Externalizable
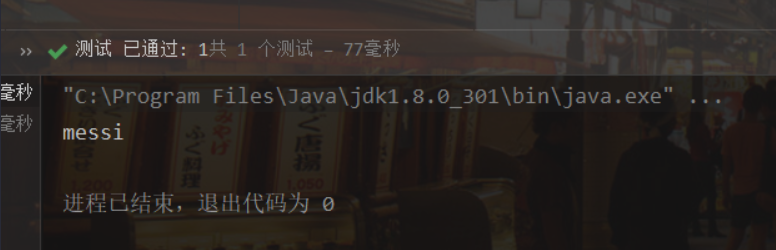
代码举例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 @Test public void test1 () ObjectOutputStream stream = null ; try { stream = new ObjectOutputStream(new FileOutputStream("object.data" )); stream.writeObject(new String("messi" )); stream.flush(); } catch (IOException e) { e.printStackTrace(); } finally { if (stream != null ) { try { stream.close(); } catch (IOException e) { e.printStackTrace(); } } } } @Test public void test2 () ObjectInputStream stream = null ; try { stream = new ObjectInputStream(new FileInputStream("object.data" )); Object o = stream.readObject(); System.out.println((String) o); } catch (IOException e) { e.printStackTrace(); } catch (ClassNotFoundException e) { e.printStackTrace(); } finally { if (stream != null ) { try { stream.close(); } catch (IOException e) { e.printStackTrace(); } } } }
运行结果如下
定义Person类,需要类继承Serializable接口(Serializable接口仅仅作为一个标识),并定义public static final long serialVersionUID
凡是实现Serializable接口的类都有一个表示序列化版本标识符的静态变量:
1 private static final long serialVersionUID;
serialVersionUID用来表明类的不同版本间的兼容性。 简言之,其目的是以序列化对象进行版本控制,有关各版本反序列化时是否兼容。
如果类没有显示定义这个静态常量,它的值是Java运行时环境根据类的内部细节自动生成的。若类的实例变量做了修改,serialVersionUID 可能发生变化。故建议,显式声明。
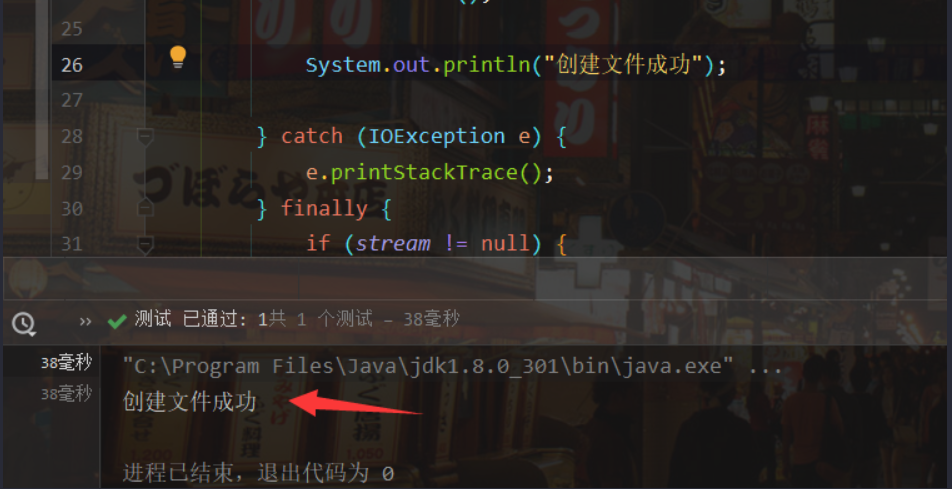
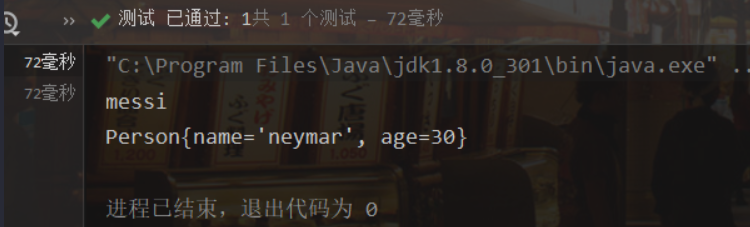
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 import java.io.Serializable;import java.util.Objects;public class Person implements Serializable public static final long serialVersionUID = 9950L ; private String name; private int age; public Person () public Person (String name, int age) { this .name = name; this .age = age; } public void setAge (int age) this .age = age; } public void setName (String name) this .name = name; } public int getAge () return age; } public String getName () return name; } @Override public String toString () return "Person{" + "name='" + name + '\'' + ", age=" + age + '}' ; } @Override public boolean equals (Object o) if (this == o) return true ; if (o == null || getClass() != o.getClass()) return false ; Person person = (Person) o; return age == person.age && Objects.equals(name, person.name); } @Override public int hashCode () return Objects.hash(name, age); } } @Test public void test1 () ObjectOutputStream stream = null ; try { stream = new ObjectOutputStream(new FileOutputStream("object.data" )); stream.writeObject(new String("messi" )); stream.flush(); stream.writeObject(new Person("neymar" ,30 )); stream.flush(); System.out.println("创建文件成功" ); } catch (IOException e) { e.printStackTrace(); } finally { if (stream != null ) { try { stream.close(); } catch (IOException e) { e.printStackTrace(); } } } } @Test public void test2 () { ObjectInputStream stream = null ; try { stream = new ObjectInputStream(new FileInputStream("object.data" )); Object o = stream.readObject(); System.out.println((String) o); Person p = (Person) stream.readObject(); System.out.println(p); } catch (IOException e) { e.printStackTrace(); } catch (ClassNotFoundException e) { e.printStackTrace(); } finally { if (stream != null ) { try { stream.close(); } catch (IOException e) { e.printStackTrace(); } } } }
运行过后生成了object.data文件
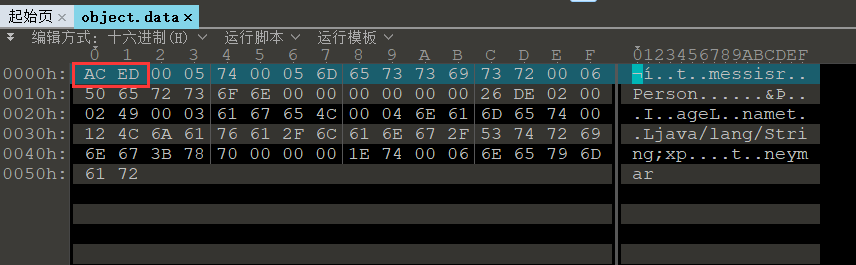
我们用二进制编辑器打开可以看到文件头为ACED,证明为序列化后的文件,0005为序列化协议的版本
然后我们再进行反序列化的操作,使用FileInputStream还原为java对象
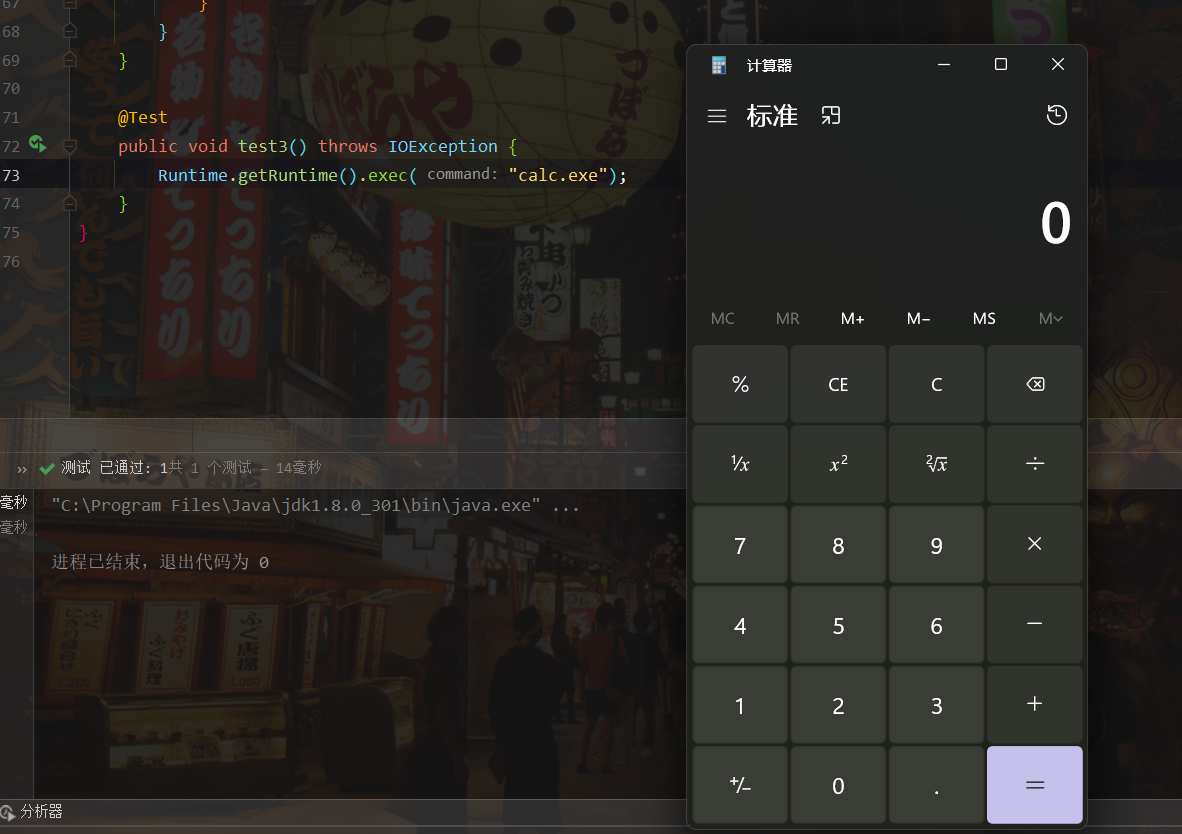
反序列化可能产生的漏洞 在java中使用Runtime.getRuntime().exec()来执行系统命令,如使用Runtime.getRuntime().exec("calc.exe");弹窗
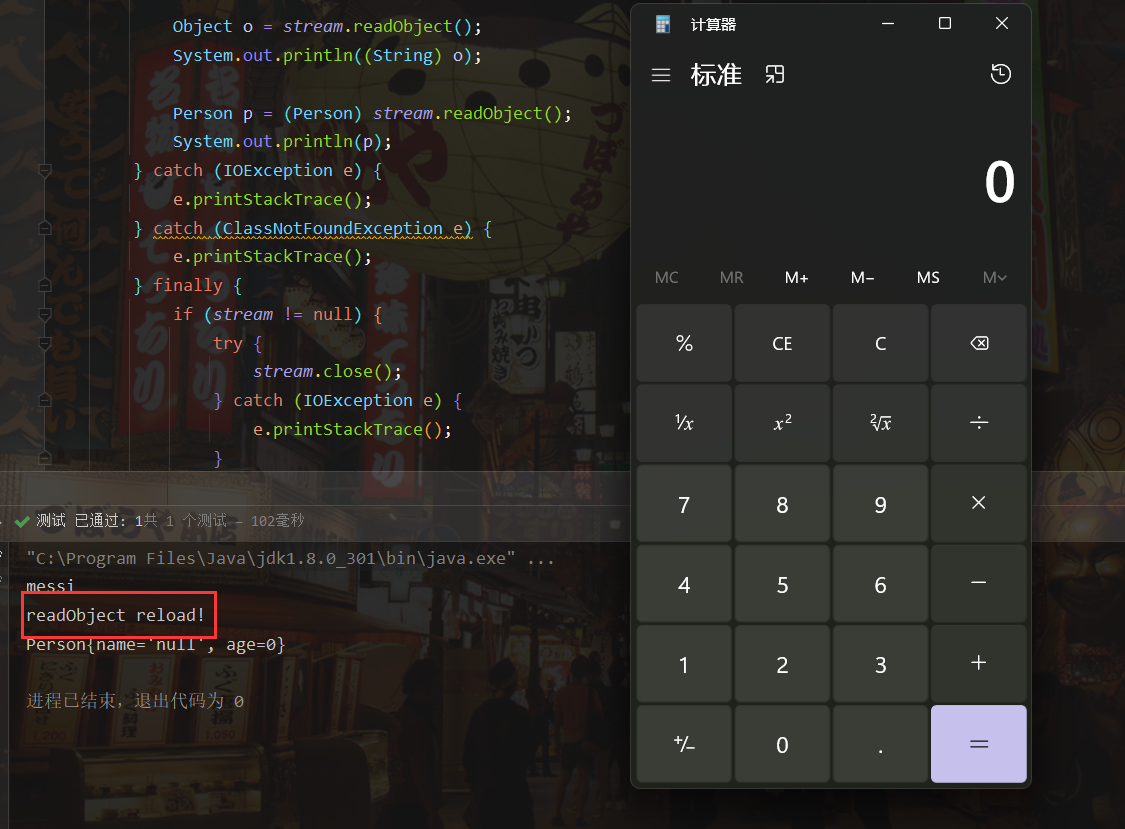
我们知道在反序列化的过程中需要调用readObject来进行输出,那么如果我们在实现了Serializable的类里将readObject重写,则会执行我们重写后的readObject方法,我们在里面添加一行执行系统命令的代码
1 2 3 4 5 6 private void readObject (ObjectInputStream input) throws IOException, ClassNotFoundException System.out.println("readObject reload!" ); Runtime.getRuntime().exec("calc" ); }
可以发现执行了我们重写的readObject方法,所以如果readObject方法存在漏洞则恶意代码可能被执行